第321章 AI芯片(2/2)
完 地减少了神经网络预测的成本。
地减少了神经网络预测的成本。
如此一步接着一步,连绵不绝。
而供与求有需要平衡,不然的话,第一 崩溃的便是自
崩溃的便是自 。
。
只是他很快又重新被tpu的构架所 引而痴迷起来。
引而痴迷起来。
结果相加聚合神经元状态。
只有
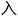 一个项目,才能彻底
一个项目,才能彻底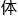 会他的乐趣。
会他的乐趣。
第二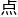 ,也是更关键的。
,也是更关键的。
难怪说站在 人的肩膀上就是
人的肩膀上就是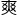 。
。
正如林奇最初所推崇的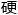 件。
件。
某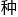 程度而言,计算量的负荷和电网的负荷很类似,最大的负荷便决定了整的
程度而言,计算量的负荷和电网的负荷很类似,最大的负荷便决定了整的 峰所在(计算难度),也决定了接
峰所在(计算难度),也决定了接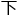 来他完成“ai芯片”后所能够到达的峰。
来他完成“ai芯片”后所能够到达的峰。
tpu芯片直接封装了神经网络计算工 。
。
林奇忍不住皱眉看了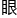 周围。
周围。
万丈楼平地起,曾经的林奇开发cpu时,第一步门选择完成的模块便是加法 ,因为它的原理最简单,也是最容易实现的
,因为它的原理最简单,也是最容易实现的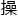 作。
作。
因此懂是第一步环节。
诸如矩阵乘法单元,统一缓冲区,激活单元等,它们以后十数个级指令组成,集中完成神经网络推理所需要的数学计算。
让他自己来设计,如何能够突破看似最简单的加法这个关卡?
本章已阅读完毕(请击一章继续阅读!)
林奇越看,越发忍不住啧啧称奇。
如此一来,矩阵里的乘片与取片,都需要大量的cpu周期与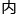 存,而tpu这芯片,便是为了减轻这负荷而生。
存,而tpu这芯片,便是为了减轻这负荷而生。
这tpu的架构居然采用了量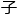 技术,在预设的最大值和最小值与八位整数之间的任意值的近似过程里,tpu居然包
技术,在预设的最大值和最小值与八位整数之间的任意值的近似过程里,tpu居然包 了足足六万五千五百三十六个八位整数乘法,直接将32位或者16位的计算压缩成为8位。
了足足六万五千五百三十六个八位整数乘法,直接将32位或者16位的计算压缩成为8位。
林奇不禁 慨万分。
慨万分。
如此特 ,让它在神经网络计算收敛方面拥有非凡的效果,曾经几天才能训练
,让它在神经网络计算收敛方面拥有非凡的效果,曾经几天才能训练 的成功,现在一小时不到就能够完成。
的成功,现在一小时不到就能够完成。
这冥冥中的呼应,也让林奇有些哭笑不得。
这也是棋类活动里,容易门的象棋比起围棋受众要光,而五棋又比起象棋还有光。
 理说,三个输而只有两个神经元与一个单层神经网络的话,权重与输便要六次乘法……
理说,三个输而只有两个神经元与一个单层神经网络的话,权重与输便要六次乘法……
数据乘以权重,表示信号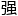 度。
度。
使用激活函数调节神经元参数活动。
然而整个tpu芯片,居然本质上也是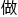 加法?
加法?
它的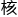 心便是由乘加组合形成的256x256的运算阵列:乘法矩阵。
心便是由乘加组合形成的256x256的运算阵列:乘法矩阵。
打个比方,传统cpu是逐行打印,而tpu芯片则能够到影印效果。
同时它又采用了典型的risc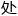 理为简单计算提供指令。它的矩阵乘法单元而不是传统的标量理,得以在一个时钟周期,以矩阵作,完成数十万个作。
理为简单计算提供指令。它的矩阵乘法单元而不是传统的标量理,得以在一个时钟周期,以矩阵作,完成数十万个作。
实现了曲线的离散化。